Appearance
Lecture2: Markov Decision Process

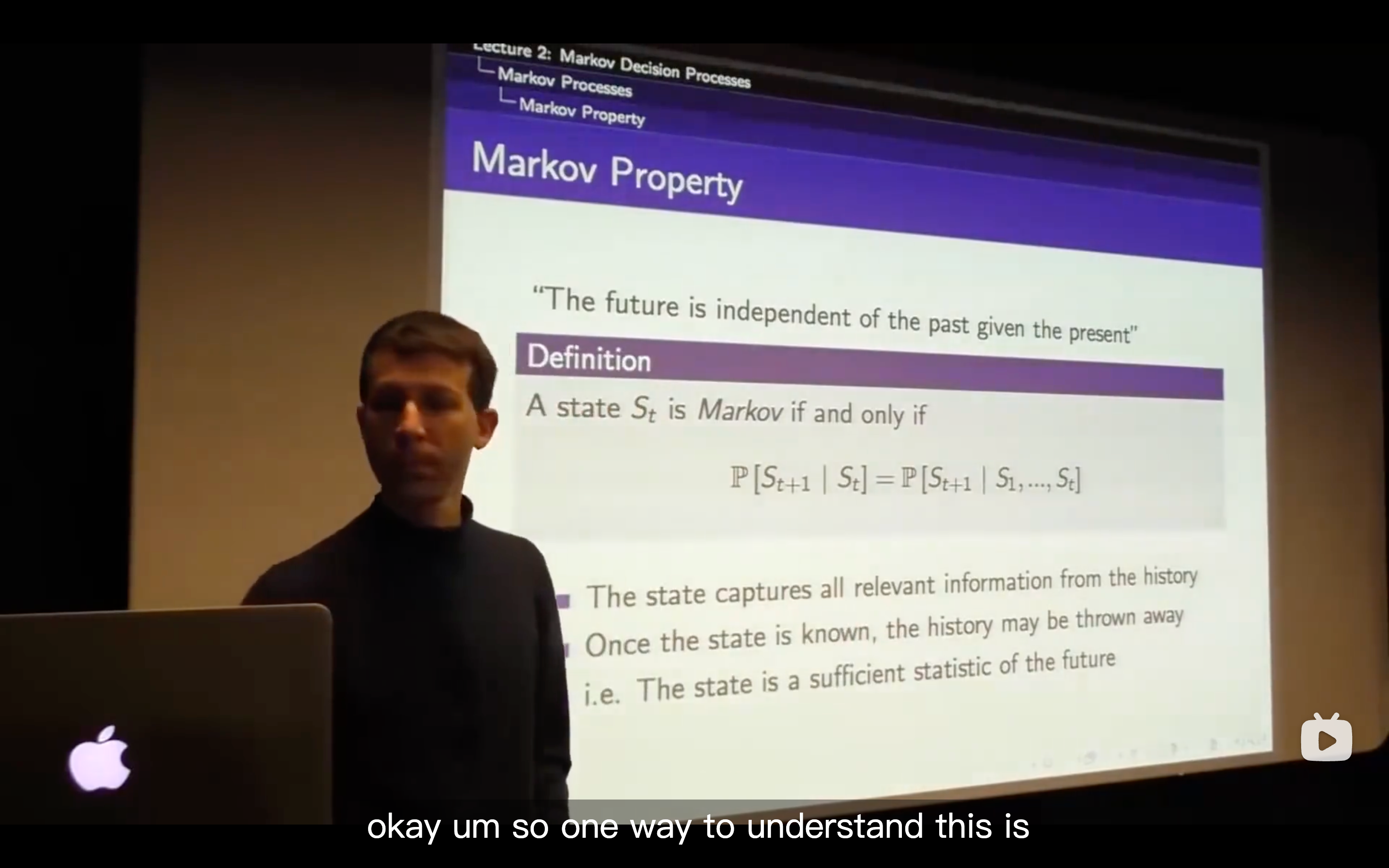

- Each row of this matrix tells us what will happen for each state that I was in.
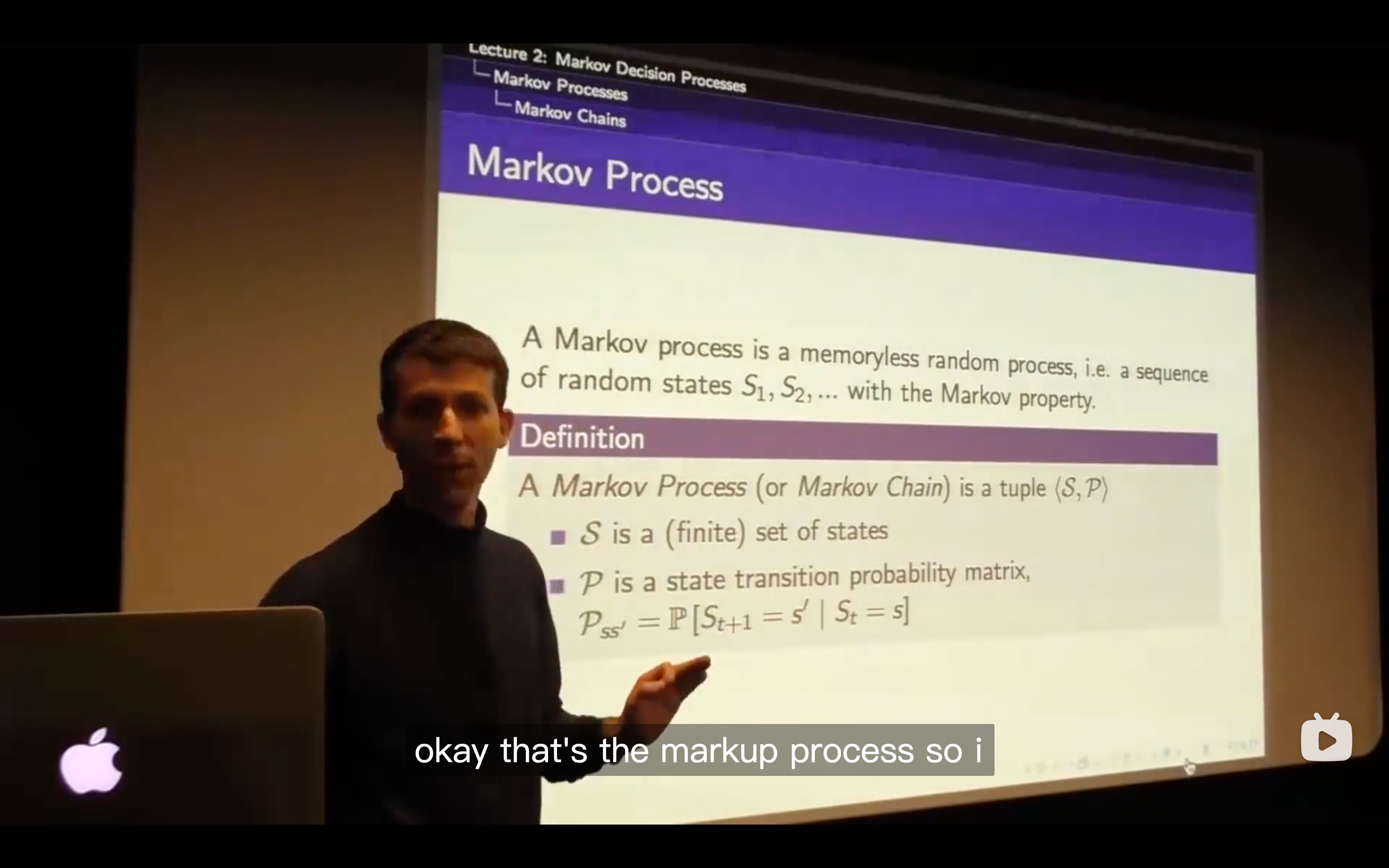
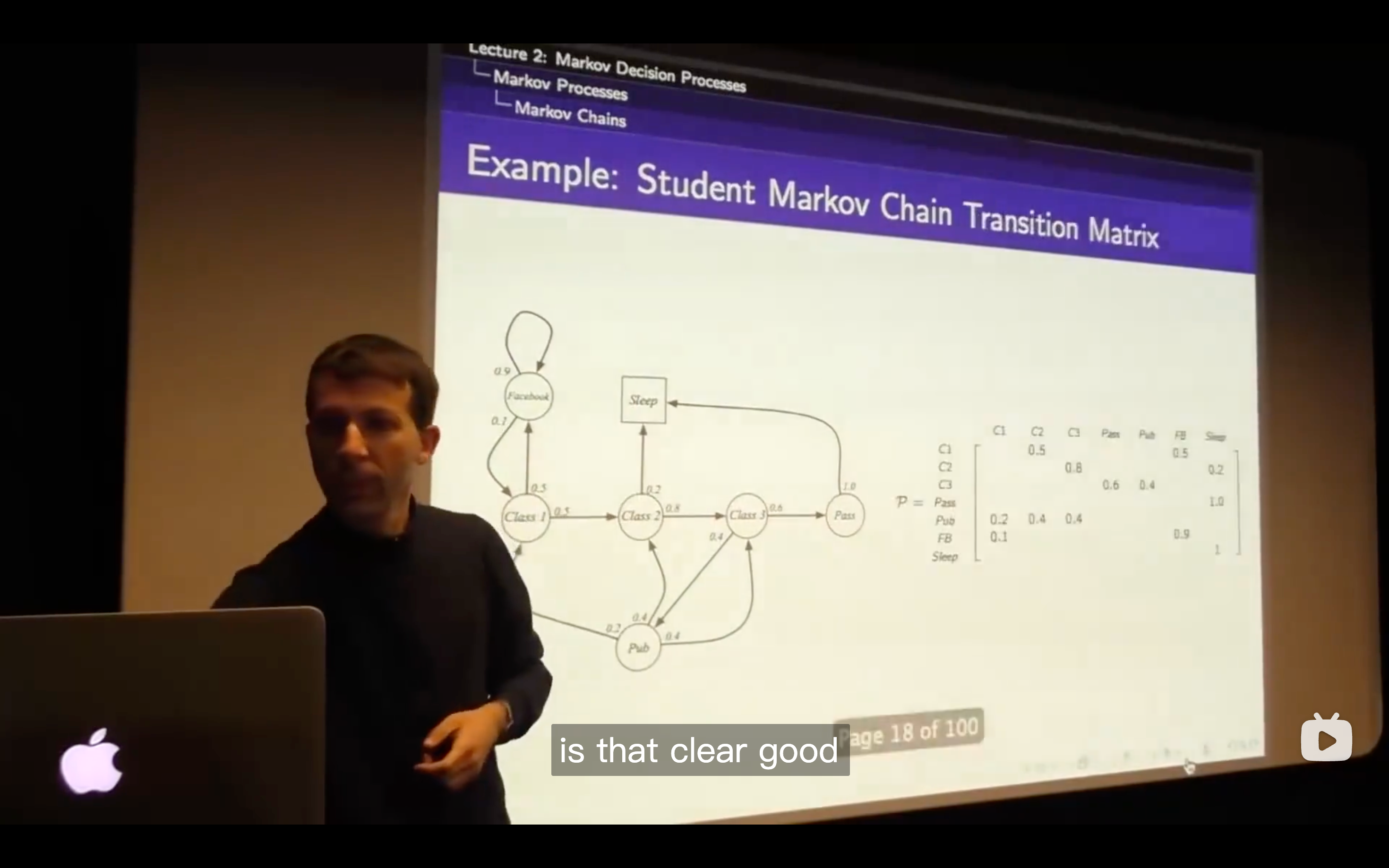
This example gives an explicit explanation for how the matrix was built
Markov Reward Process.
- It is the Markov process with some value judgement


refers to the"goal", the goal is to maximize the sum of all of these rewards - For
: - 0 kind of means maximally short-sighted, which shows that you basically zero anything beyond your current time step and you only look at that first reward
- 1 is maximally fast sighted where you care about all rewards going infinitely far into the future



- Bellman equation may be the most fundamental relationship in RL



- It is the Markov process with some value judgement
Markov Decision Process
Policies
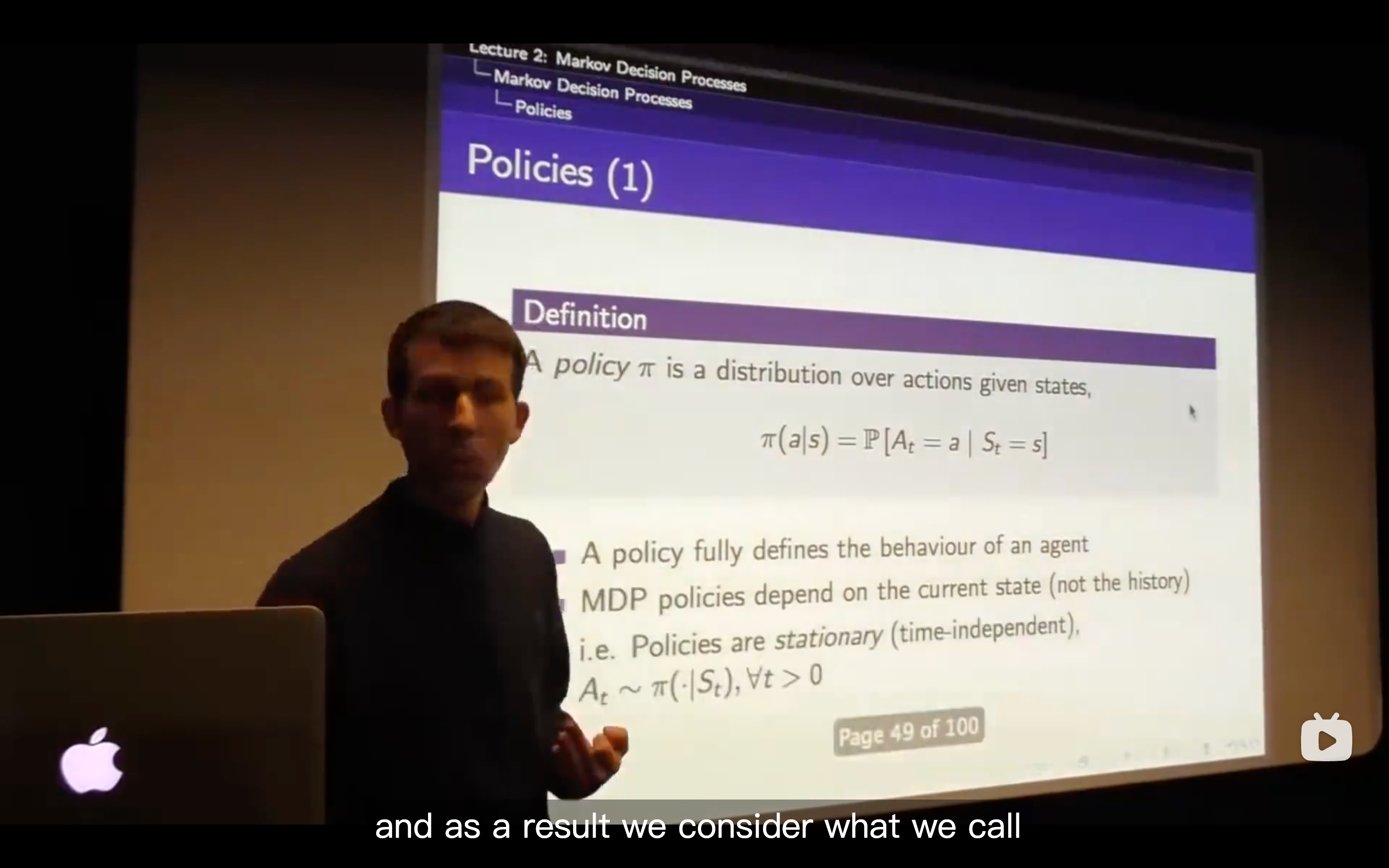
- What we want to do is maximizing the reward from now onwards that the way we' going to behave optimally.
- Our definition of state information-wise includes all the information about the expected future

Value function

- state-value function
- The
tells us how good is it to be in state s if I'm following policy
- The
- action-value function
- state-value function
Bellman Expectation Equation


- it basically tells us now we really know how good is it to be in each one of these states you really will get 7.4 units of reward in expecation if you just behave according to this policy.
- Under the policy of this example, we do everything with the probability of 50 percent.
- In this map, the reward does depend on the action you take
Optimal Value Function


Optimal Policy


- An optimal policy can be found by maximising over action-value function.

The max of the q values can be achieved by picking up the max of values of each of the actions that you can take from that state.




- All you need to do is to figure out how do I behave optimally for one step, and the way you behave optimally for one step is to maximize over those optimal values functions in the places you might end up in.
