Appearance
Lecture4: Model-Free Prediction
Introduction

Monte-Carlo Learning





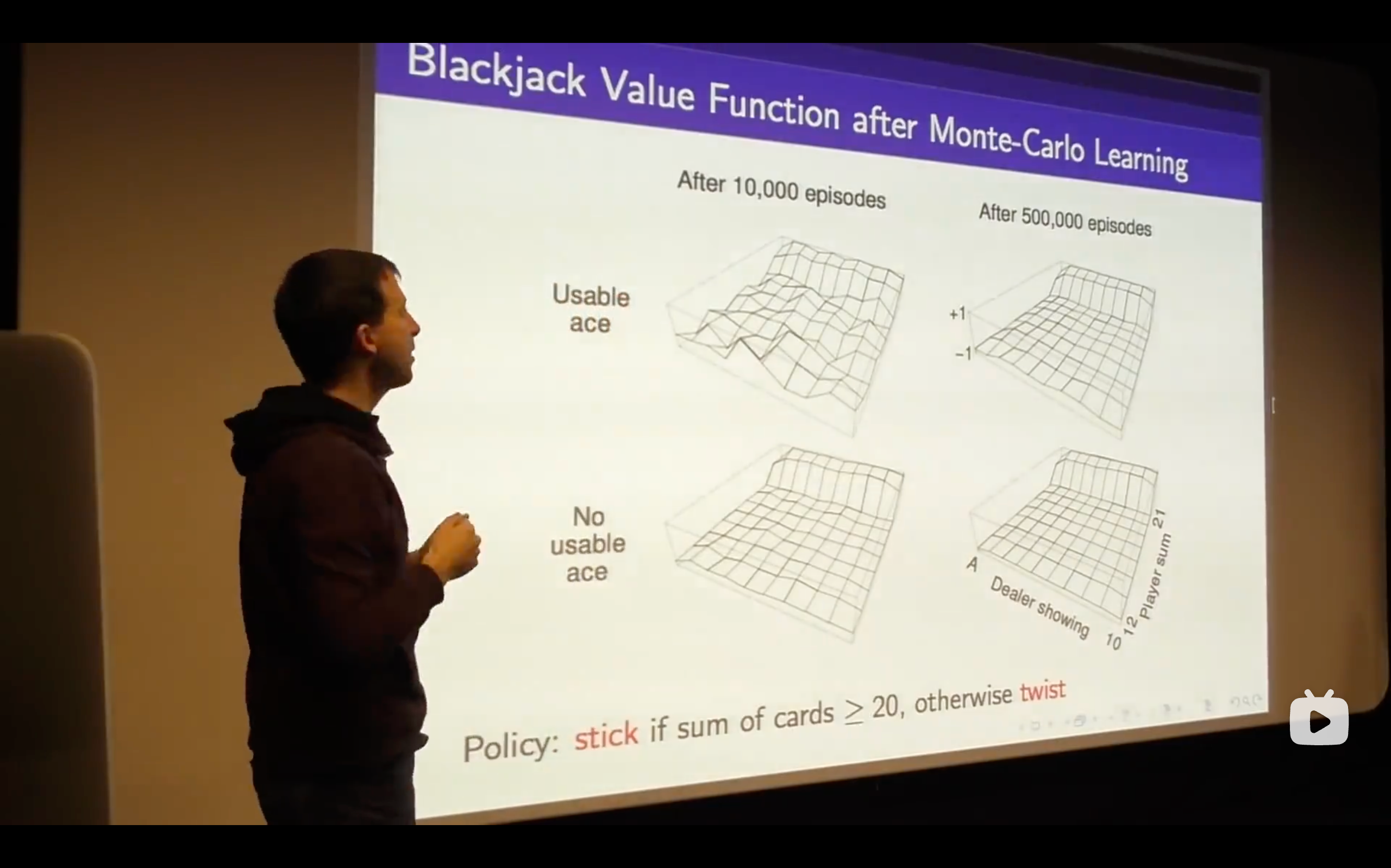
- We see that emerging nicely from the structure of this value function just by sampling, so no one told us the dynamics of the game ( that means no one told us the probabilities that govern yhe game of blackjack), this is just by running episodes, trial and error learning, and figuring out the value function directly from experience.
- The expected reward is the value function.


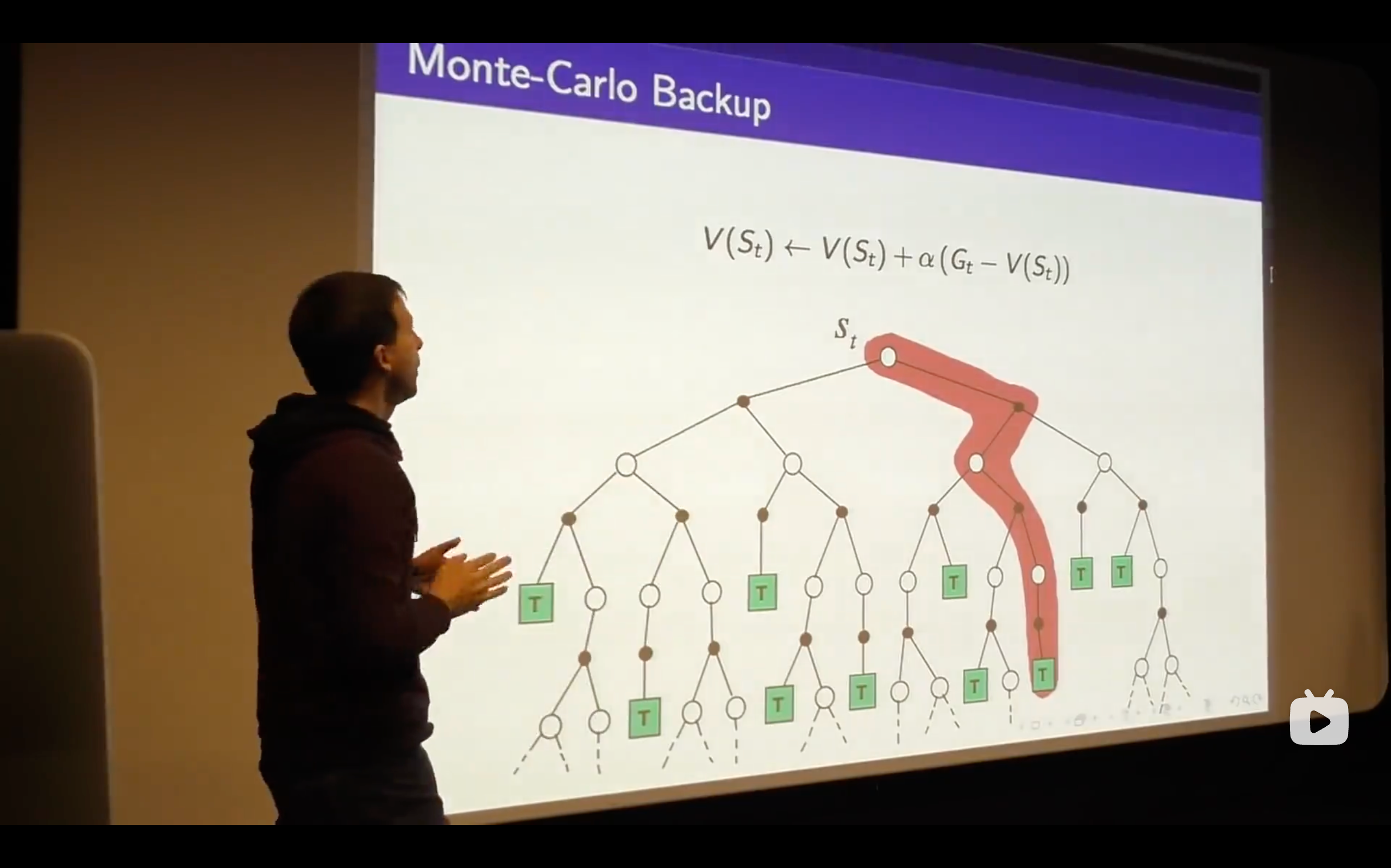
- So that's the Monte-Carlo Learning, a very simple idea that you run out episodes you look at those complete returns that you've seen and you update your estimate of the mean value towards your sample return for each state that you visit.
Temporal-Difference Learning

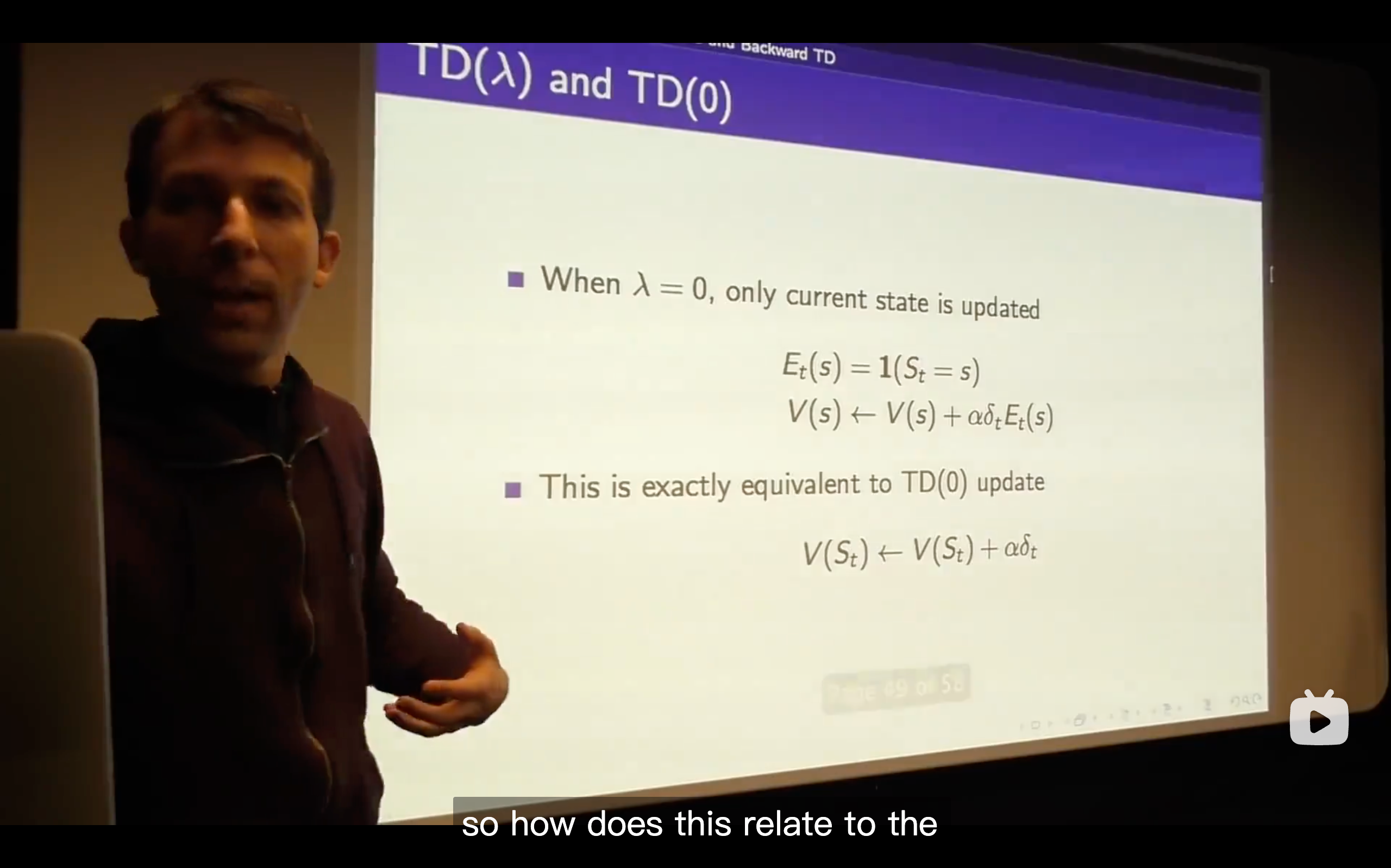
Bootstrapping is the fundamental idea behind TD learning.

The TD target is like a random target which depends on exactly what happens over the next time step but we get some immediate reward and some value wherever we happen to end up and we're going to move towards that TD target.
In Monte-Carlo, you wouldn't get the negative reward or be able to update your value for your prediction, but in TD learning, you can immediately update the value function you had before and be capable to change your future decision.
We changed our predicted total time based on each state just happened to us.
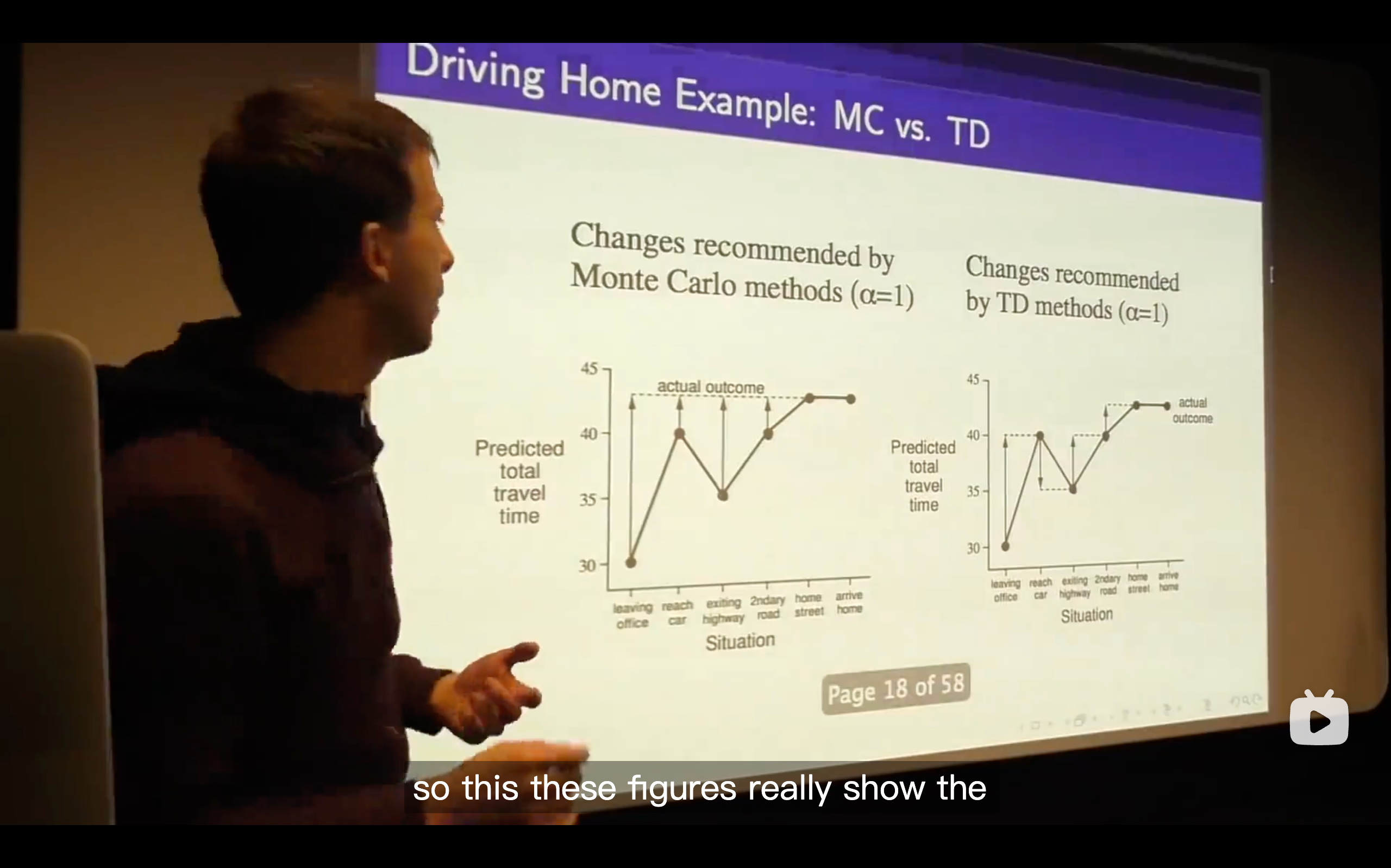
Each step along this when using monte-carlo learning, you update towards the actual outcome you have to wait until you finally get the final state, seeing the actual travel time and then updating each of your value estimates along the way.
.Whereas with TD learning it's quite different. At every step, it's like you started off thinking it's going to take you how long, after one step you thought can be changed. So in other words, you can immediately update your predicted total travel time instead of waiting until anything else happened.

What's the meaning of TD learning?
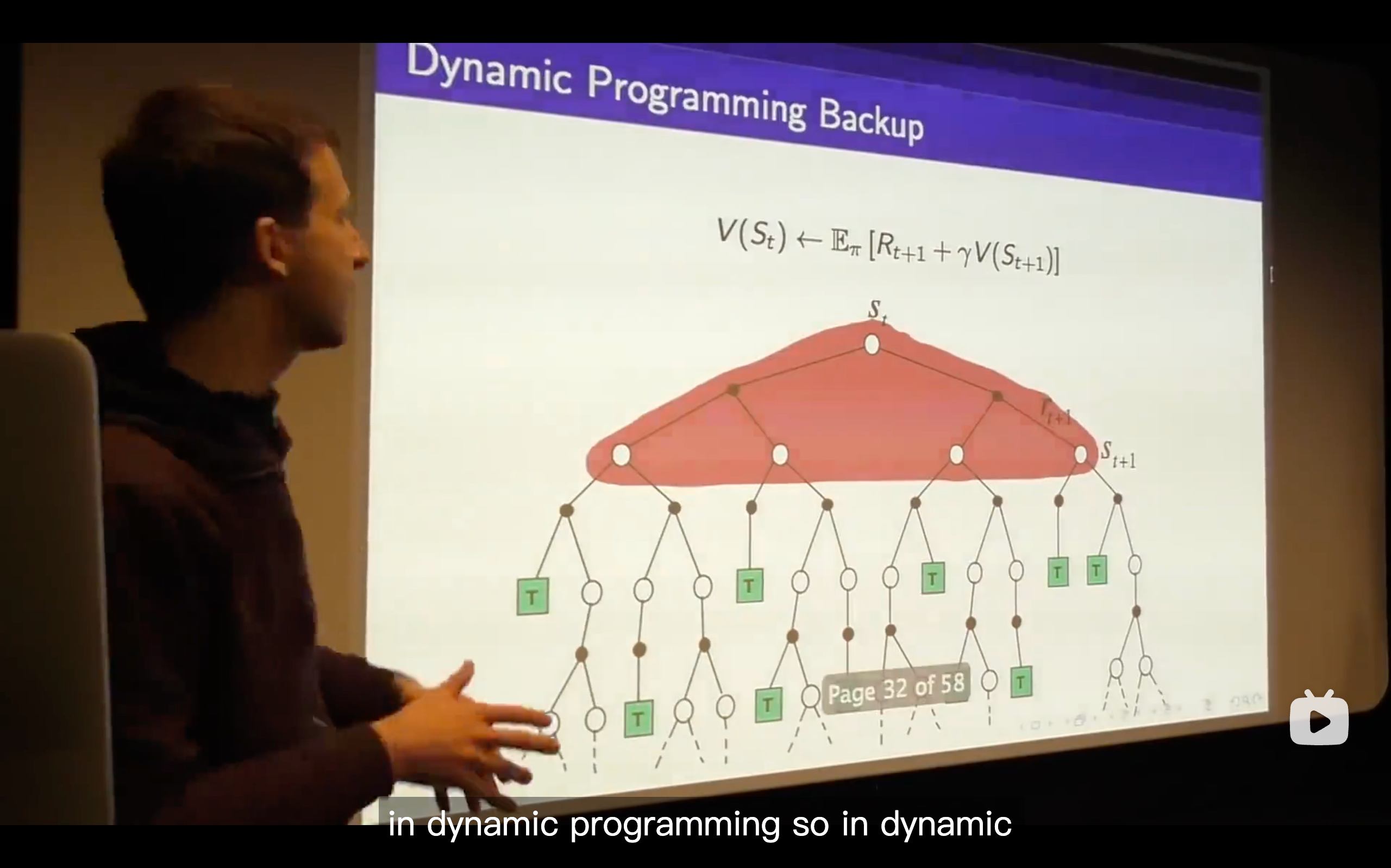
- The basic answer is that in the TD, it finds the true value function as long as you run this thing out, it will always ground itself because even though you correct yourself based on your guess and that guess might not be right, that guess will then be updated towards something that happens subsequently which will ground it more and more, so all of your guesses are progressively becoming better and that information backs up such that you get the correct value function.

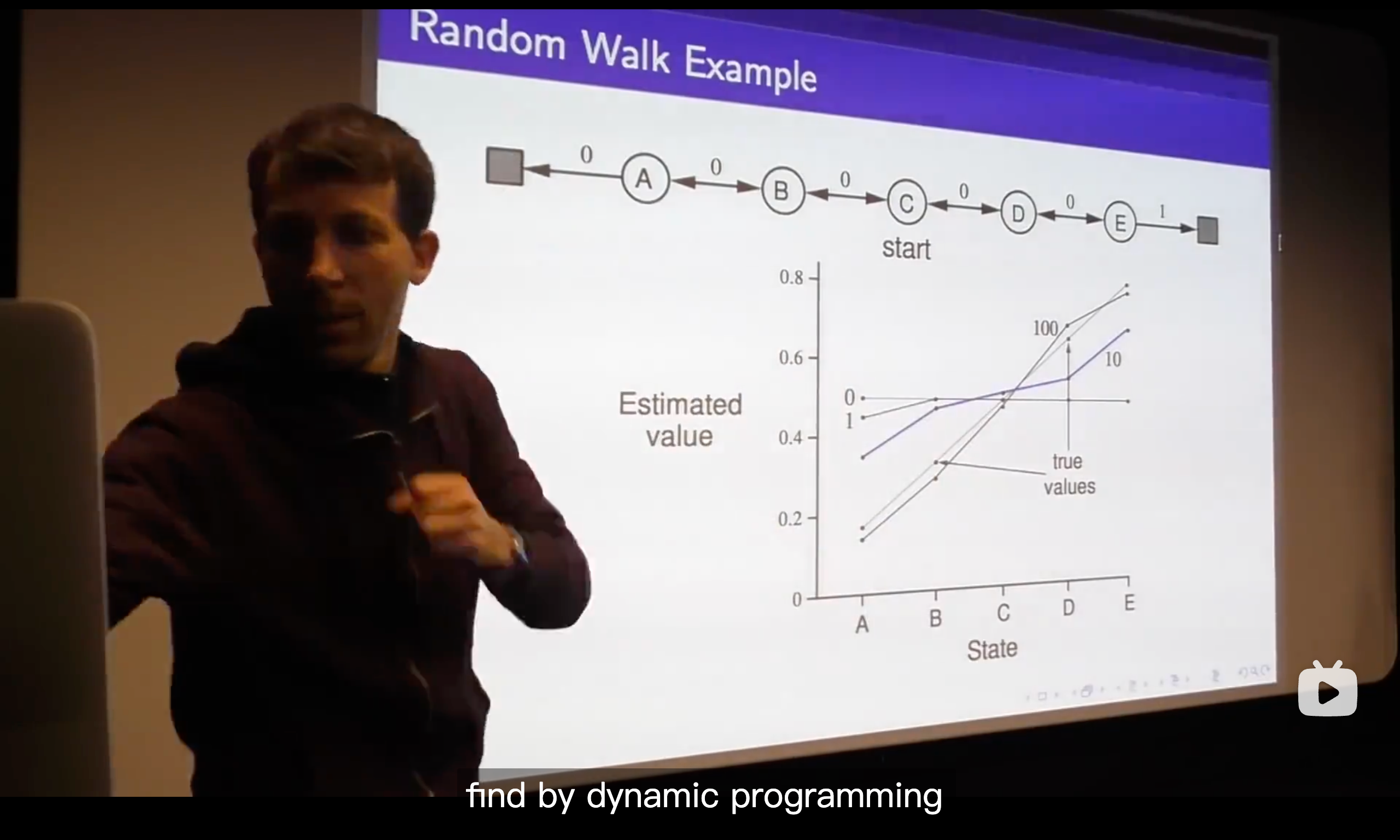

- TD is trying to explain the data in the best possible way.




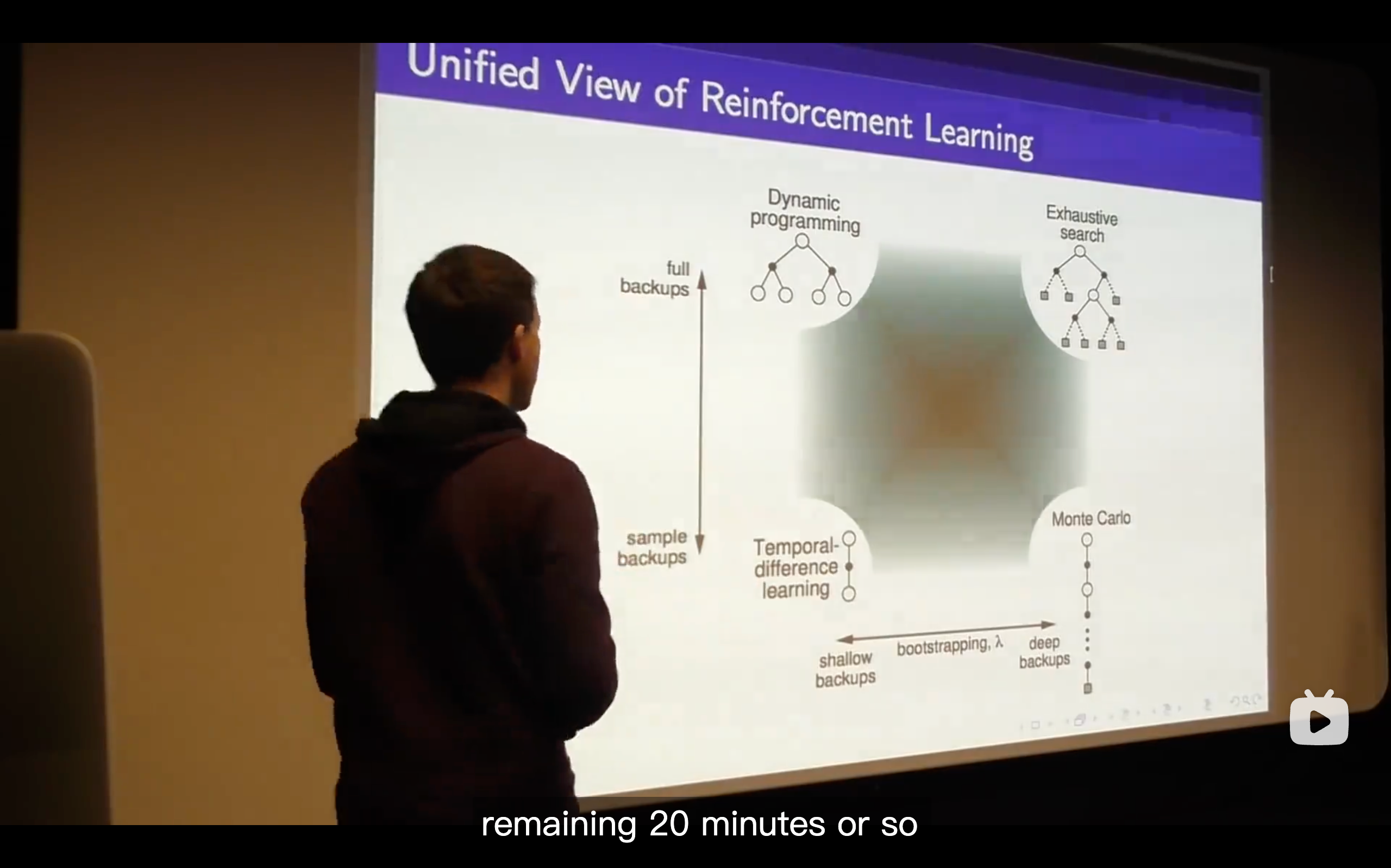
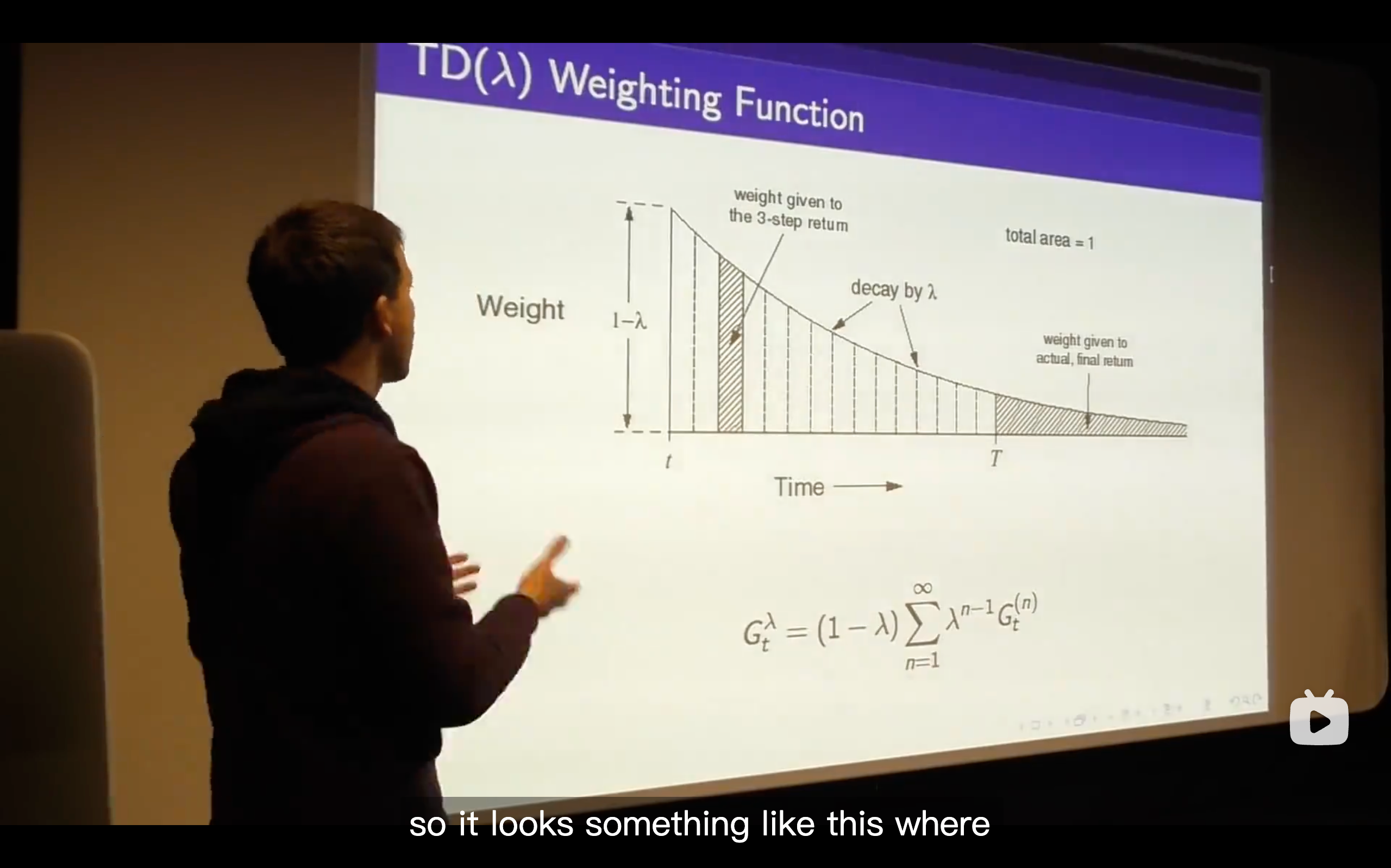
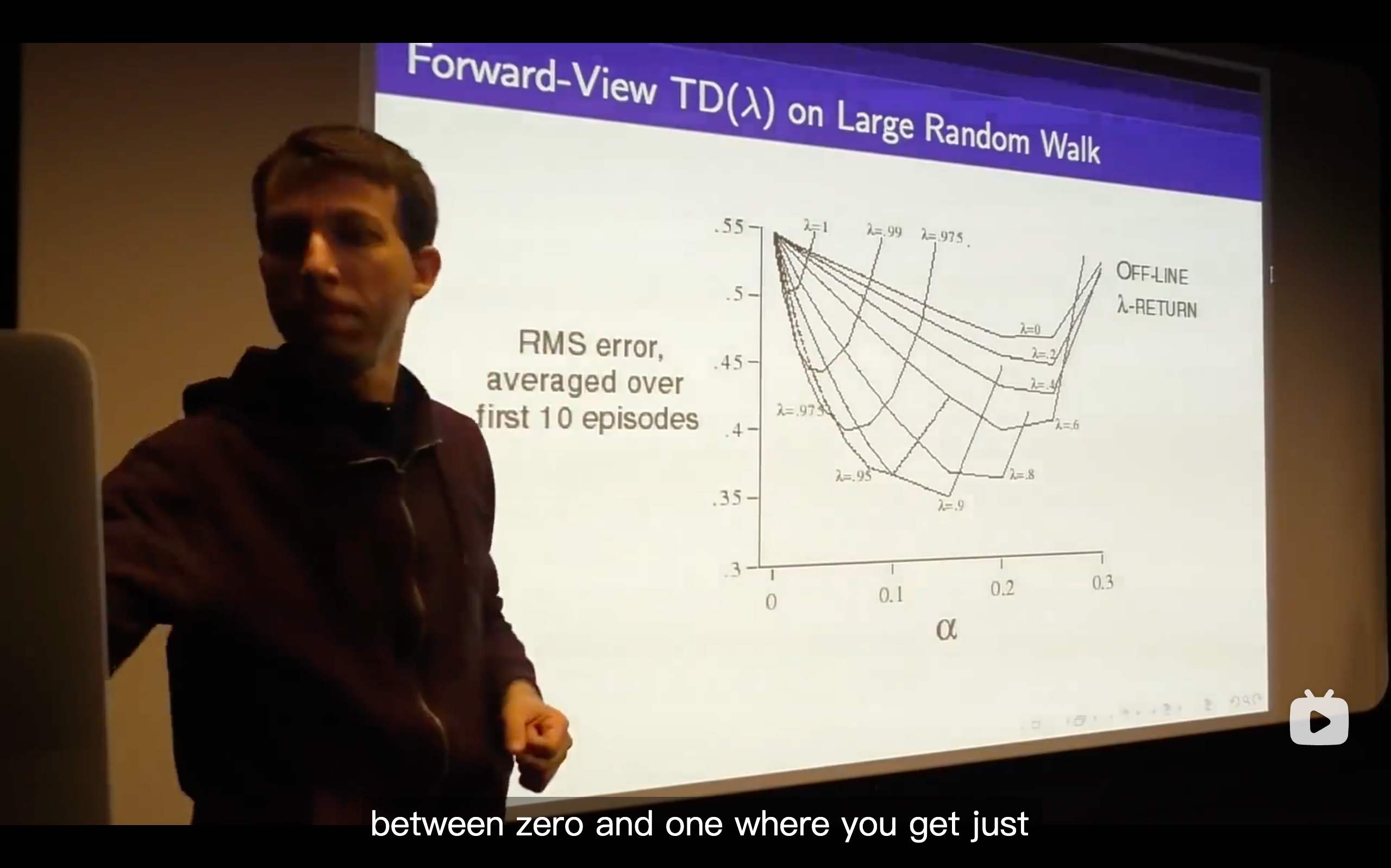
TD(
) (The generlizing function of TD learning, which enhancing the n from 1 to endless.) 

- What we talk about is just whether we do online or off-line updates and that means whether we immediately update our value function or whether we defer the updates of our value function until the end of the episode.
- So what we're going to do is trying to come up with the best all of n and that's the goal to efficiently consider all n at once.


- (1 -
) is a normalizing factor.