Appearance
Lecture5: Model-Free Control




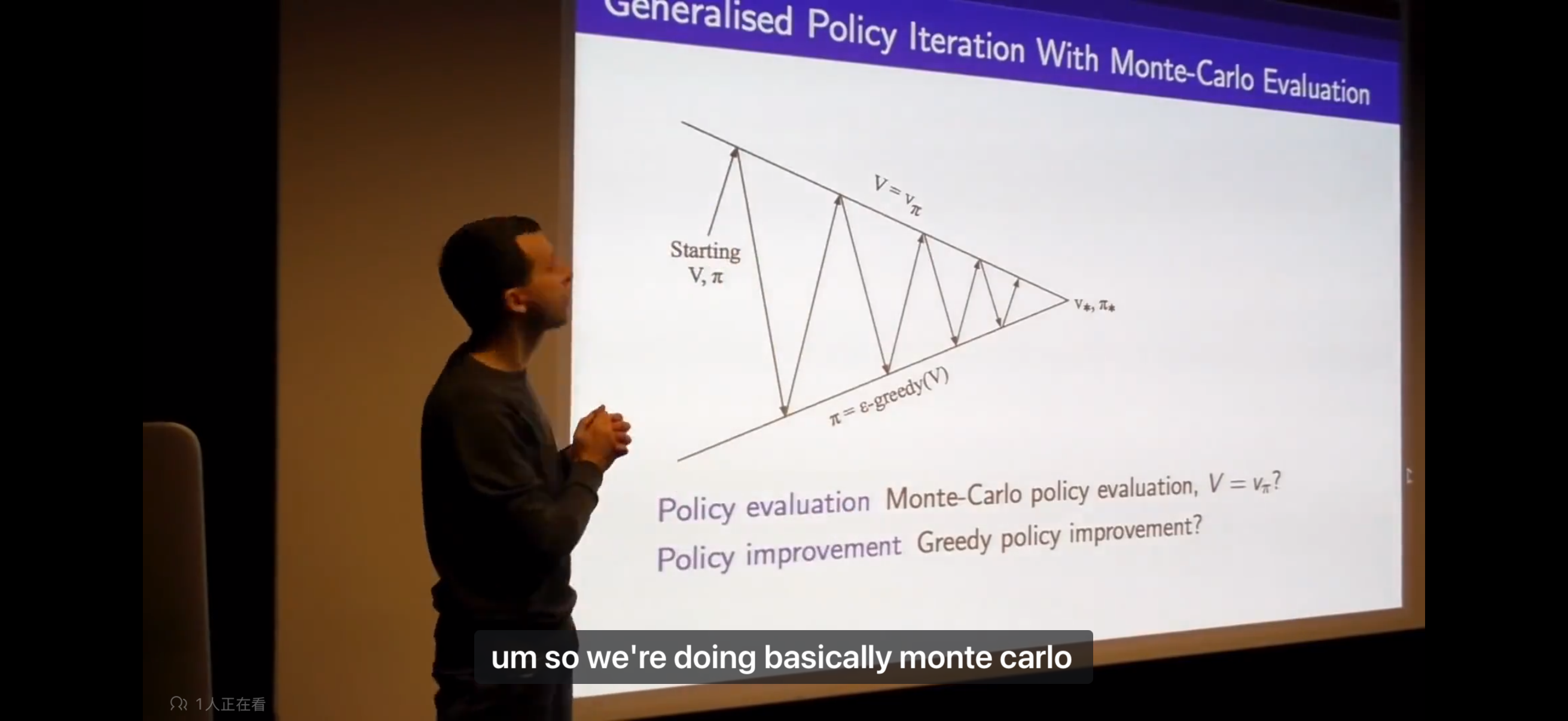

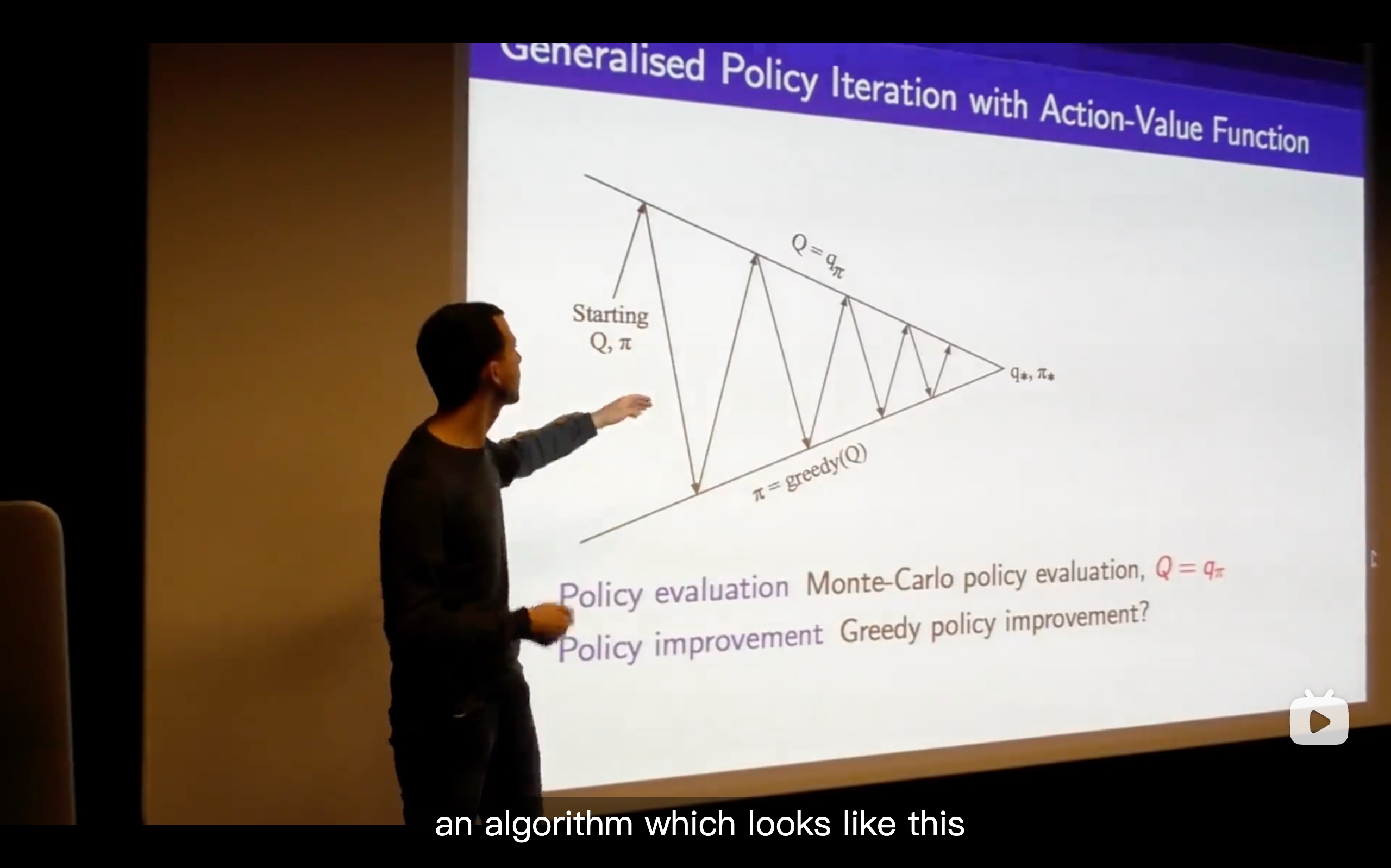

- You need to carry on exploring everything to make sure that you understand the the true value of all of your options. If you stop exploring certain actions, you can end up making incorrect decisions, getting stuck in some local incorrect optimum showing that your beliefs can be incorrect.


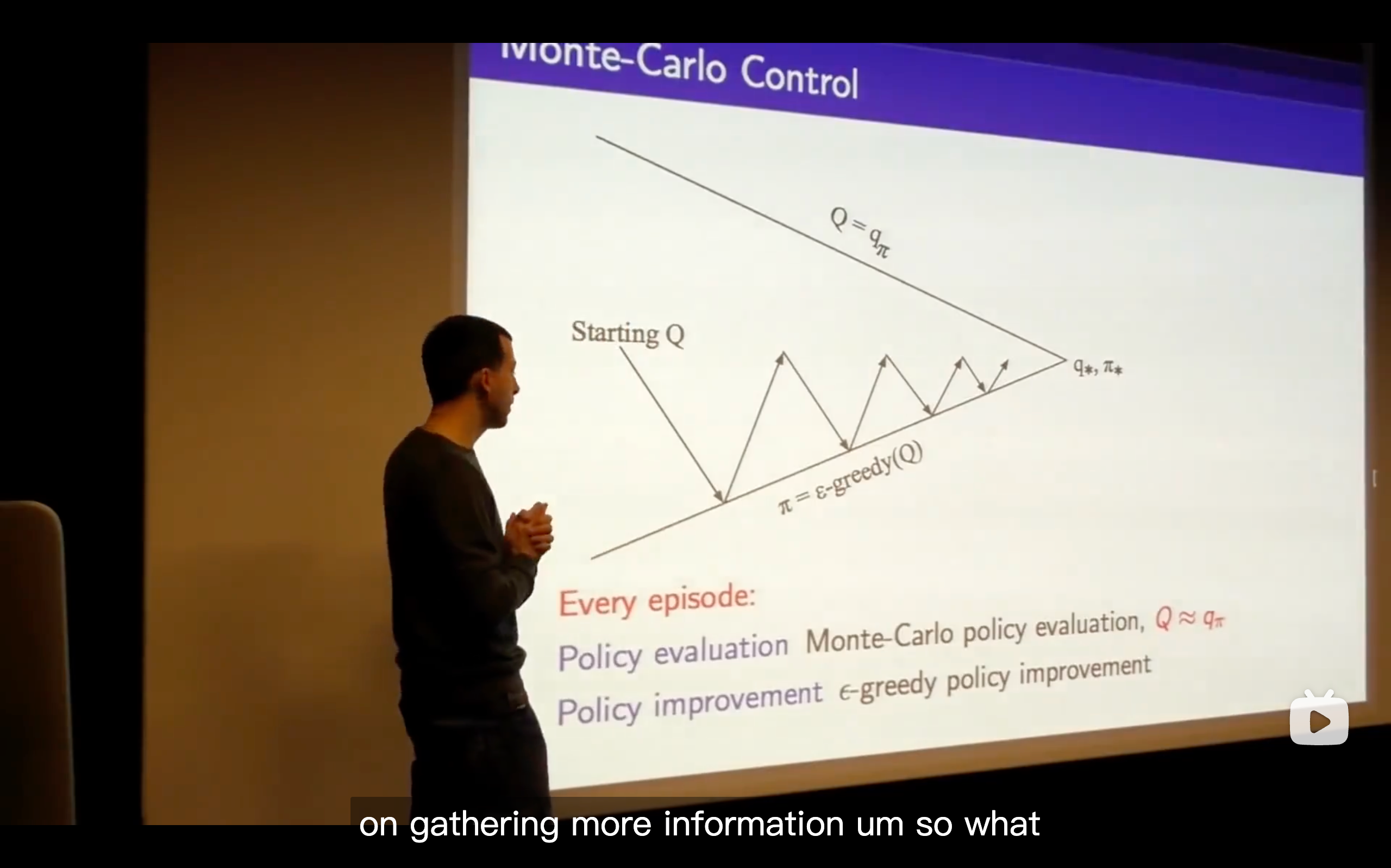




- Sarsa: State-Action-Reward-State-Action
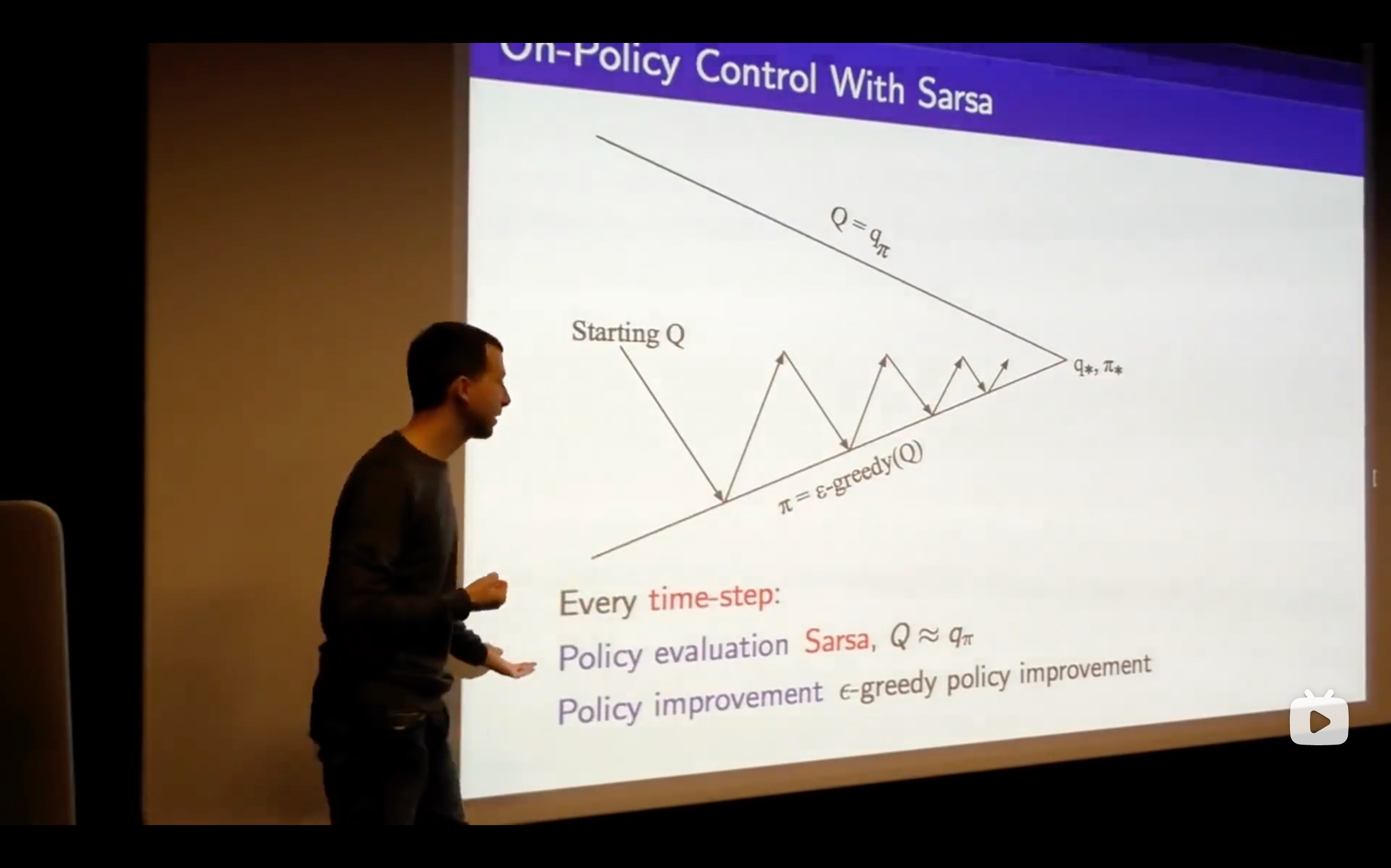



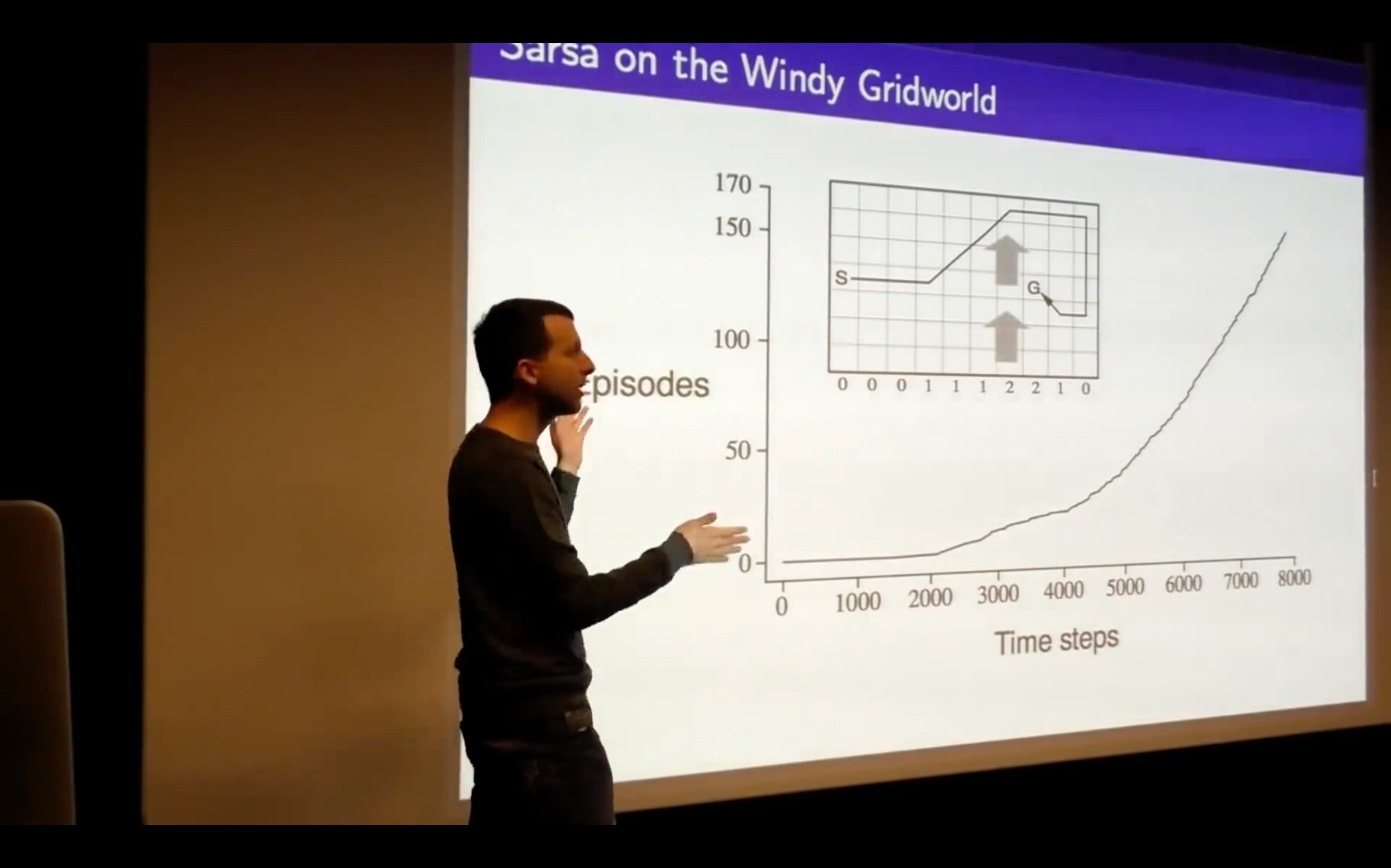


- What's the problem of this?
- This isn't an online algorithm, it's not something where we can take one step, update our Q-vlaue and immediately improve our policy, but we would like to be able to run things online and be able to get the freshest possible updates ,then updating immediately.



https://chat.qwen.ai/s/t\_53c20bd8-dfc6-4204-886f-74ecba03690f?fev=0.1.9


: Target Policy : Behaviour Policy
- Change P sampling into Q sampling.
- importance weight:




