Appearance
Lecture3: Planning by Dynamic Programming
Intro


Planning in an MDP
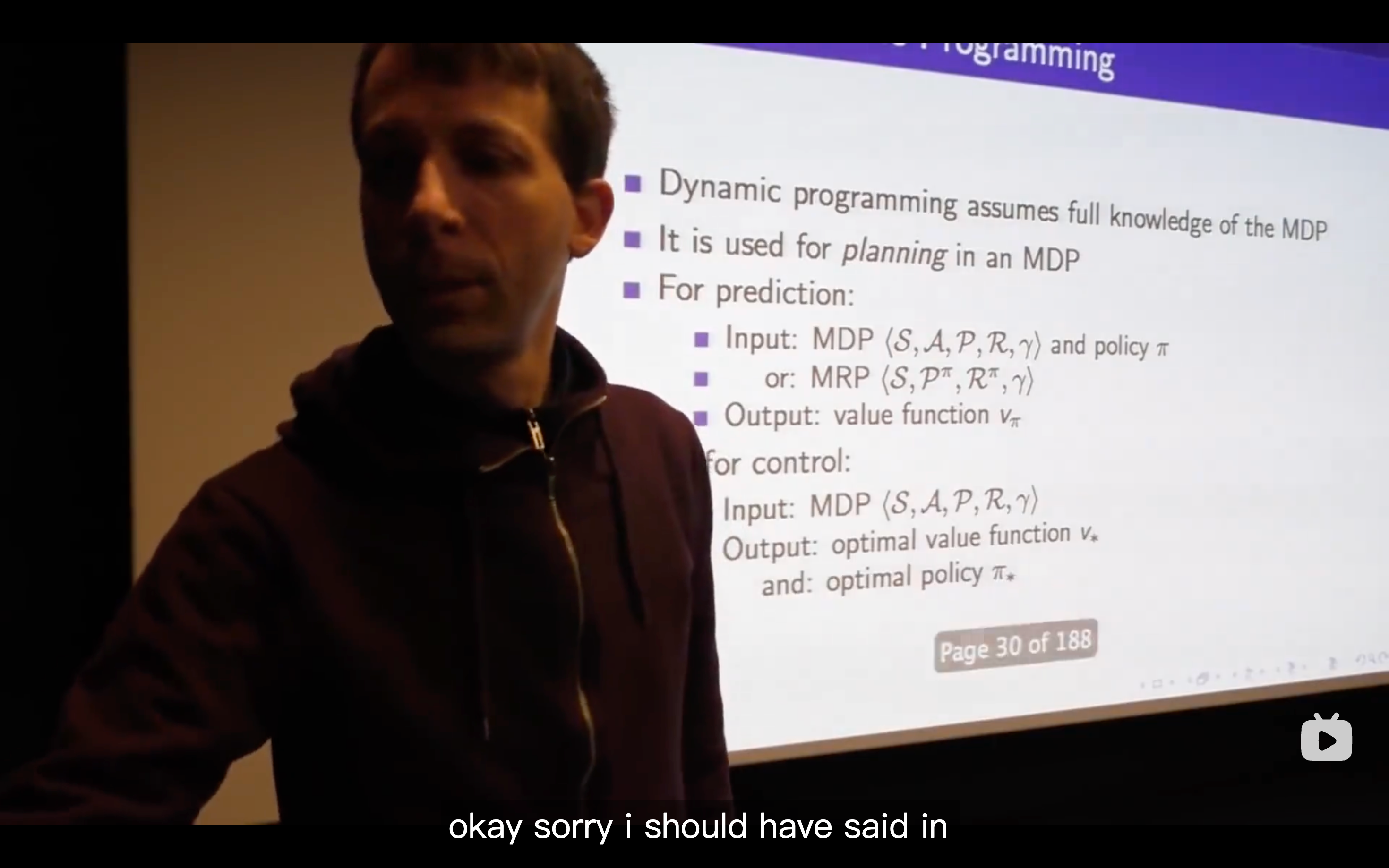
What's a Dynamic Programming solving?

Policy Evaluation





Policy Iteration

- There's always at least one deterministic optimal policy for any MDP, so it's sufficient to actually search over deterministic policies only when youre looking for the optimal policy.
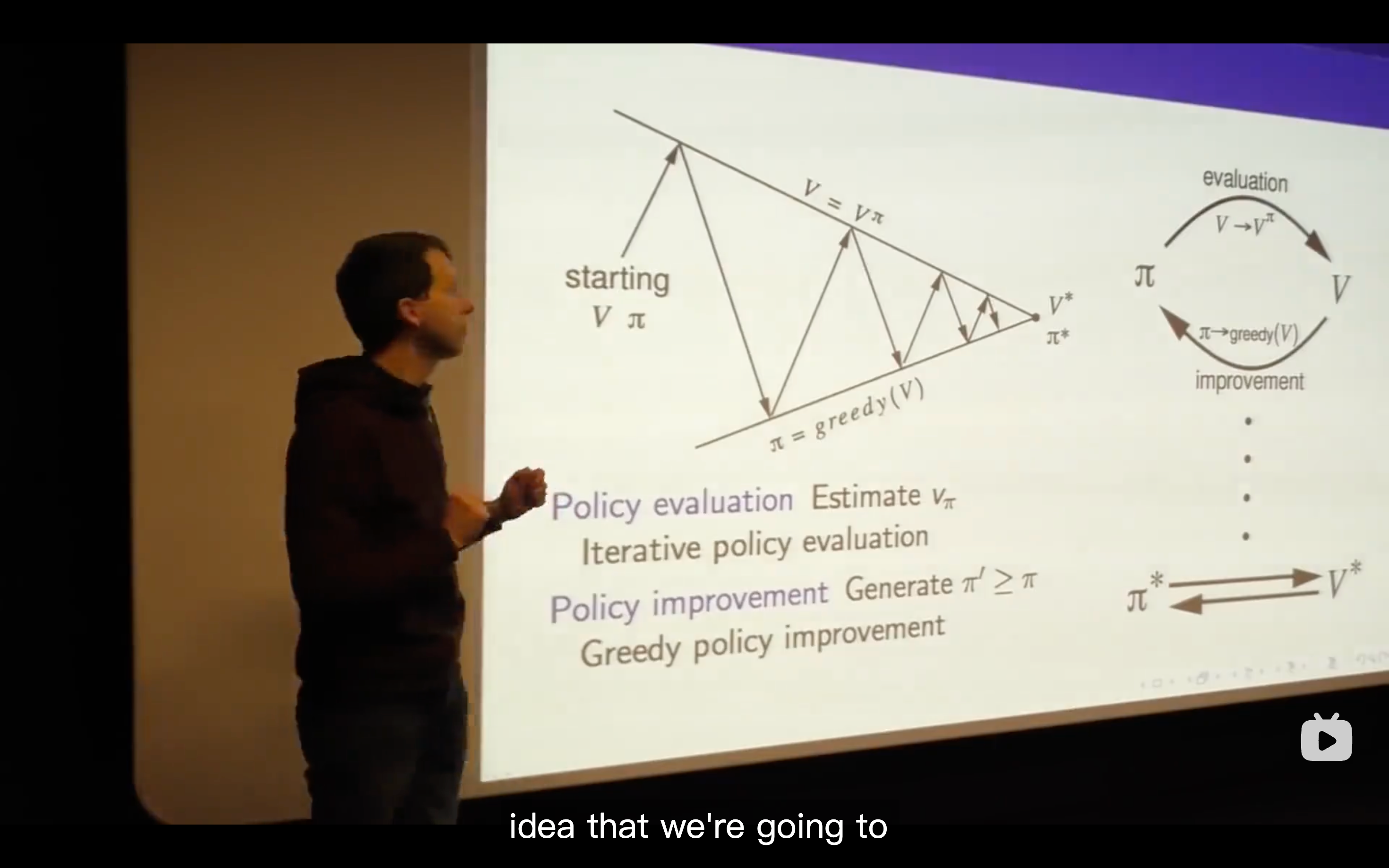
- No matter where you start for any value and any policy, you will always end up with the optimal value function and the optimal policy.

- This is a contour map of this policy, the density of these grid worlds represent the speed of value changing. The more, the faster.
- evaluate the policy, then come up with a new surface( which is in the representation of value function in a two dimensional axes.)
- There's no cost in moving a car in this example.

- The
is just the immediate reward plus the value of the next, that's what we act greedily. - Let's not worry yet about what happens after that, let's just consider one step and see whether we get more value over one step.
- The max over the
has to be at least greater than equal to one particular so the max over all actions has to be at least as good as one particular action that we could plug in which is what the one we were choosing before. - So all of this that's a long-winded way to say that the value function improves over one step at least that if we just take our
for one step, we'll get at least as much reward as the policy we started with. - So we don't make things worse ever, we always make things at least make them better, (though) we haven't yet said that this is guaranteed to keep getting better or to reach the optimal value.
- Being greedy doesn't mean that we only look at one step of immediate reward, instead, it means that we look at the best action we can take if we optimize over all actions we can do for one step, and then look at our value function which summarizes the whole future —— all future rewards we're going to get going into the future but under our previous policy.

- There's always at least one deterministic optimal policy for any MDP, so it's sufficient to actually search over deterministic policies only when youre looking for the optimal policy.
Value Iteration

- So if my first action is optimal and then after that I follow an optimal policy from wherever I end up then we can say that the overall behavior is optimal。


Artificial Intelligence: Foundations of Computational Agents -- Value Iteration Demonstration

- So if my first action is optimal and then after that I follow an optimal policy from wherever I end up then we can say that the overall behavior is optimal。
